A Fictional History of Numbers, Part 2: Measurement, Estimation, Completeness, and Reality
This week we continue our exploration of what numbers are, and where mathematicians keep finding weird ones.
In part 1, we started with the natural numbers, the most basic numbers we use to count things, and invented the integers (negative numbers) and the rational numbers (fractions). Then we took the same ideas a little further, and got the algebraic numbers, which are solutions to polynomial equations with rational coefficients—basically all the equations we can get by starting with the natural numbers and using just addition and multiplication.
But there are other questions we can ask, which don’t always give algebraic answers. So today we’ll look at a different question that we might want our numbers to answer: how do we measure things?
But before we start, if you like my writing and want to see more of this project, I have a Ko-Fi account. Any tips would be appreciated and would help me write more essays like this. Let me know what you’d like to hear about!
Finding Area
Last time we left off with a question: what is the area of a circle of radius 1? You probably know the answer: the area of a circle is given by the formula \( \pi r^2\), so if the radius is \(1\) the area must be \(\pi\). But where did that formula come from? And what about the number \(\pi\)—what exactly is it?
If we draw a quick picture, we can make a rough estimate of the area. The circle is contained inside \(2 \times 2\) square, so it must have area less than \(4\); and it contains a \(1 \times 1\) square, so it must have area bigger than \(1\). But we want to be a bit more precise.
One option is just to draw more, smaller squares.
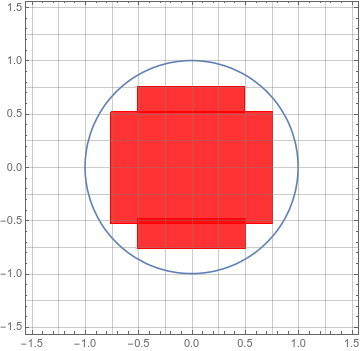
Each of these squares is \(\dfrac{1}{4} \times 1/4\) and so has area \(1/16\). We can count that the circle contains \(32\) of them, and so has area at least \(\frac{32}{16} = 2\).
Conversely, we can contain the circle with \(60\) squares, so the circle has area less than \(\frac{60}{16} = \frac{15}{4} = 3.75.\)
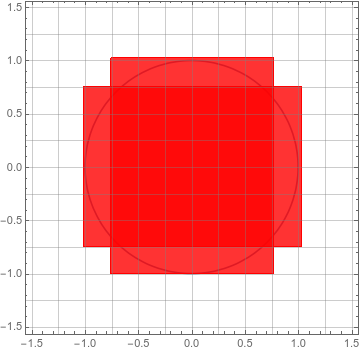
So we have an estimate for the area \(A\) of our circle: \(2 < A < \frac{15}{4}.\) But this estimate still isn’t very good. We can improve it by drawing a finer grid, with more, smaller squares; but this gets tedious really quickly.
I’m not going to count the squares in this picture, but I could.
This gives us a way to think about the area of this circle. By drawing finer and finer grids, we can get better and better estimates of the area of the circle.
Formulaic estimation
As a mathematician, I’m a very specific kind of lazy. I’m much too lazy to count up dozens of tiny squares, but I am willing to make very complicated, abstract, and possibly confusing arguments to avoid counting the squares. So I want to estimate the area of this circle in a more formulaic way, so I don’t have to count anything.
Let’s pretend the circle is a pizza. We can cut it into eight slices, like this:
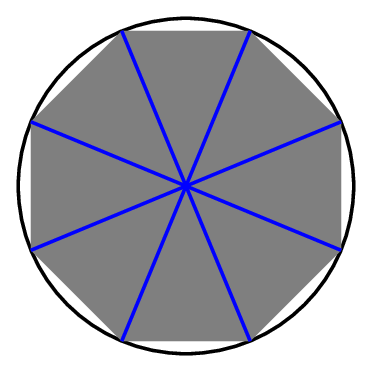
If we join the points where we slice through the crust together, we get an octagon around the outside. That lets us replace our difficult question with a simpler one: what is area of this octagon? The octagon is made up of eight triangles, and we know the area of a triangle is \( \frac{1}{2} b h \), where \(b\) is the length of the triangle’s base, and \(h\) is the triangle’s height. So the area of the octagon is \(4 bh\).

The triangle’s height is roughly the radius of the circle, which is \(1\); and the length of the base is roughly one eighth of the circumference of the circle. And since we’re just estimating, rough numbers are fine; we can say that
\[ \text{Area of circle} \approx \text{Area of Octagon} \approx 4 \cdot \frac{\text{circumference}}{8} \cdot 1 = \frac{\text{circumference}}{2}, \] so the area of the circle of radius 1 is about half its circumference. In fact, we can make this same argument for a circle of any radius: if the radius is \(r\) and the circumference is \(C\), then the area will be approximately \(\frac{1}{2} C r.\)
But these are all just rough estimates. The area of the octagon isn’t exactly \(\frac{1}{2} Cr\), and the area of the circle isn’t exactly the same as the area of the octagon. But here’s where we have a key insight, which the Greeks called the method of exhaustion1: both of those approximations get better if we draw a shape with more sides. Here’s the same basic picture, but instead of an octagon, we drew a sixteen-sided hexadecagon:
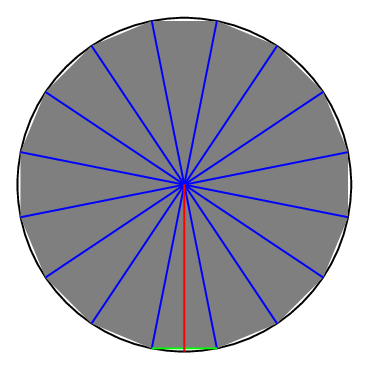
We have sixteen triangles, which have still have a height or about \(r\), but have bases of length about \(\frac{C}{16}\). This gives a total area of roughly
\[ \text{Area of Circle} \approx \text{Area of Hexadecagon} \approx 16 \cdot \frac{1}{2} \cdot \frac{C}{16} \cdot r = \frac{1}{2} C r. \]
And next we have a \(32\)-sided icosidodecagon.2
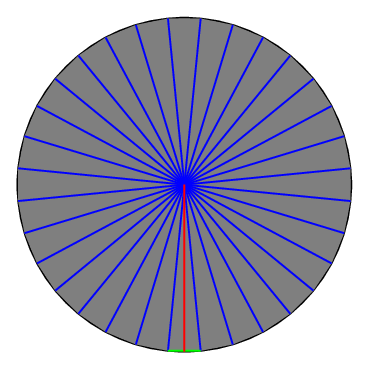
The grey area isn’t the whole circle, but I can’t actually see the difference.
The icosidodecagon is still not quite the same size as the circle, but it’s pretty close. So we get an even better approximation:
\[ \text{Area of Circle} \approx \text{Area of Icosidodecagon} \approx 32 \cdot \frac{1}{2} \cdot \frac{C}{32} \cdot r = \frac{1}{2} C r. \]
More importantly, we can see that as the number of sides goes up, all of our approximations get better: the polygon is closer to being a circle, the height of each triangle is closer to the radius, and the base of each triangle is closer to \( \frac{C}{n} \), where \(n\) is the number of sides of the polygon. So we can tell this approximation will get better and better as the number of sides of our polygon gets bigger; we conclude that the area of a circle is exactly \[ A = \frac{1}{2} C r. \]
But that leaves us still with a problem. This isn’t the formula for the area of a circle that you know and (maybe) love. And in fact this formula is not nearly as useful as \(\pi r^2\), because it requires both the radius and the circumference. We know the radius is \(r\); but what’s the circumference?
Ring Around the Circle
I know I said I’d invent some numbers, and I promise I’m getting there soon. But we should finish answering this question first.3
We can find the circumference of a circle with the same basic method-of-exhaustion logic we used to find the area formula. If we inscribe a polygon inside the circle, the perimeter of the polygon will be roughly the circumference of the circle; and the more sides that polygon has, the better this approximation will be.
The trick is finding a polygon that we can actually estimate the circumference of. And what Archimedes noticed is that if the number of sides of the polygon is \(3 \cdot 2^n\), we can use some basic trigonometry to work this out.
A circle has \(360^\circ\) total in it. If we inscribe a hexagon, we can chop the circle into six equilateral triangles, which will each have an inner angle of \(60^\circ\). We can cut these in half to get an angle of \(30^{\circ}\)—and this is convenient, because some basic trigonometry4 can convince us that \(\sin(30^\circ) = 1/2\). This means that each side of the hexagon has length \(r\), and the perimeter of the hexagon is \(6r\).
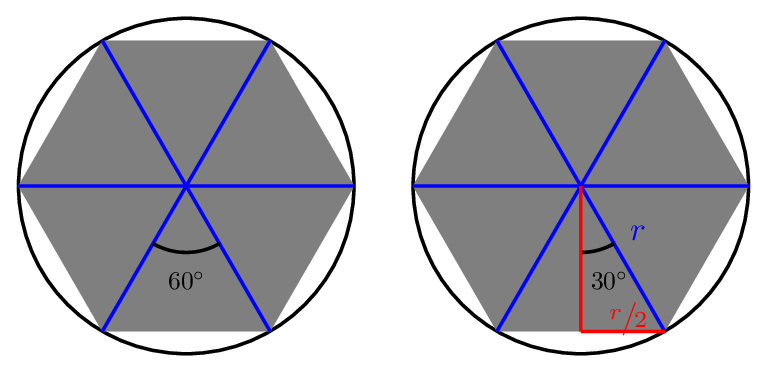
If we take a circle with radius \(1\), then each side of the hexagon has length 1, and the perimeter is just \(6\). This tells us that the circumference of the circle has to be bigger than six—but not too much bigger.
But more importantly, we can extend this argument. There’s a standard trigonometric formula5 for finding the sine of half of an angle. That means that when we look at a twelve-sided dodecagon and get an angle of \(15^\circ\), we can compute that \(\sin(15^\circ) = \frac{\sqrt{2 - \sqrt{3}}}{2}\). This tells us that each side has length \(\sqrt{2 - \sqrt{3}}\), and thus the total perimeter of the dodecagon is \(12 \sqrt{2 - \sqrt{3}}\approx 6.212.\)
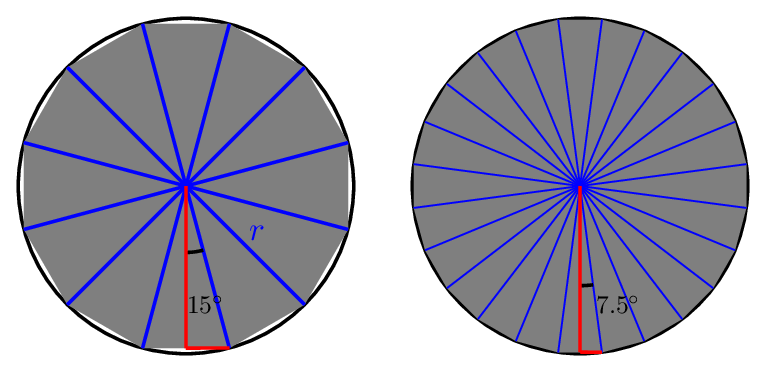
Doubling the sides again gives a \(24\)-sided icositetragon; we use the trigonometric identity again, which get a more complicated formula. But we can work out each side has length \( \sqrt{2 - \sqrt{2 + \sqrt{3}}}, \) and the whole polygon has a perimeter of \(24 \sqrt{2 - \sqrt{2 + \sqrt{3}}} \approx 6.27.\)
Another doubling gives us a \(48\)-sided shape with perimeter \(48 \sqrt{2 - \sqrt{2 + \sqrt{2 + \sqrt{3}}}} \approx 6.28,\) and one more gives us a \(96\)-sided shape with perimeter \( 96 \sqrt{2 - \sqrt{2 + \sqrt{2 + \sqrt{2 + \sqrt{3}}}}} \approx 6.28\) again. So by the Method of Exhaustion, it’s reasonable to claim the circumference is about \(6.28\).
In fact, this entire argument scales up with the radius. So if a circle has radius \(r\), then the circumference is \(C \approx 6.28 r\); and from our earlier argument, the area is \( A = \frac{1}{2} Cr \approx 3.14 r^2\). The Greeks took this number \(3.14\)6 and called it \(\pi\), the first letter of the Greek word περίμετρος (perimetros), which means “perimeter” or “circumference”. And thus we finally have the formulas you know from school:
\[
\begin{aligned}
C & = 2 \pi r \\\
A & = \pi r^2.
\end{aligned}
\]
Getting real
This argument produced a number, which we said is about \(3.14\). But what exactly do we mean when we write down the number \(\pi\)?
Limitless power
We described \(\pi\) by approximating it. It’s the number that’s close to \(6\), and closer to \(12 \sqrt{2-\sqrt{3}}\), and even closer to \(24 \sqrt{2 - \sqrt{2+\sqrt{3}}}\), and even closer to…
The Greeks called this the Method of Exhaustion, but in modern language we call it a limit. In calculus, we give a definition for limit something like this:7
Definition: If we have an infinite list of numbers \(a_1, a_2, \dots, a_n, \dots\), and another number \(L\), we say that \(L\) is the limit of the sequence \( (a_n) \) if we can approximate \(L\) as precisely as we want by choosing a large enough \(n\). We notate this by writing \(\lim_{n \to \infty} a_n = L.\)
Less formally, the number \(L\) is the limit of a sequence of numbers if the numbers eventually get really close to \(L\). The idea is that the numbers \(a_1, a_2, a_3, \dots \) are each approximations of \(L\), and as we go further into the list, they approximate it better and better—which is exactly what we did when we estimated \(\pi\) earlier.
Except there’s a problem here. If we know \(L\) is a number, this is all fine. It’s not too hard to convince yourself, say, that the sequence \(( 1, 1/2, 1/4, 1/8, 1/16, \dots )\) is getting close to zero, or that \(1/n\) is a good approximation of zero for large values of \(n\).
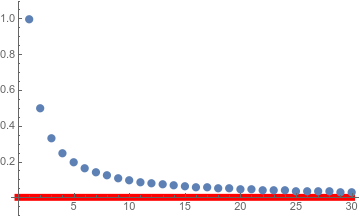
We can see that the points with heights \(1/n\) are getting closer to the red line at height \(0\). The further we get into the sequence, the better an approximation this is.
But on the other hand, if we have a list like \((1, 2, 3, 4, \dots)\), or \((-1, 1, -1, 1, \dots)\), it doesn’t look like those are approximating any number.

On the left, the sequence \((1, 2, 3, 4, \dots)\) is getting bigger and bigger without approaching any particular number. On the right, the sequence \((-1, 1, -1, 1, \dots )\) is bouncing back and forth between two values, rather than approximating one specific number.
Not every sequence has a limit, because not every sequence is approximating one particular number. So how do we know our sequence \[ \left( 3, \quad 6 \sqrt{2-\sqrt{3}}, \quad 12 \sqrt{2-\sqrt{2+\sqrt{3}}}, \quad 24 \sqrt{2-\sqrt{2+\sqrt{2+\sqrt{3}}}}, \quad \dots \right) \] does approach a number?
Unfortunately, it kind of doesn’t.
Failing at algebra
For a long time, people looked for a way to represent \(\pi\) as a rational number—as a ratio of two integers. We found that \(22/7\) is a pretty good approximation, and \(355/113\) is a shockingly good approximation (correct to six decimal places). But in 1758, Johann Heinrich Lambert proved that \(\pi\) isn’t a rational number.
Now, we do have other, “irrational” numbers. In part 1 we talked about algebraic numbers, which are solutions to polynomial equations \(a_0 + a_1 x + \dots + a_n x^n =0\). We used this technique to construct lots of irrational numbers, like square roots, cube roots, and the indescribable solutions to \(x^5+x+3=0\).
But \(\pi\) isn’t one of those, either. In 1882, the German mathematician Ferdinand von Lindemann showed that \(\pi\) is a transcendental number, which means it isn’t the solution to any polynomial equation with rational coefficients. We just can’t describe it with any of the tools we saw in Part 1.
It’s quite difficult to show that \(\pi\) is transcendental, and I’m not going to try to prove it here. The most common proof relies on the fact that the number \(e\) is transcendental, and even that isn’t easy to prove. But we do know \(\pi\) isn’t an algebraic number—so what is it?
Mind the gaps
The details are different, but we’re really in the same boat we found ourselves in last time. In part 1, we wanted a solution to the equation \(x^2-2=0\), but we couldn’t find a number that worked, so we just made one up. We can do the same thing here. When a sequence looks like it should have a limit, we’ll make one up for it.
We need to be careful, though, because lots of sequences don’t look like they’re converging anywhere, and those shouldn’t have limits.
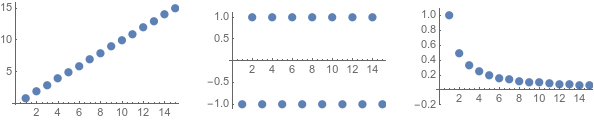
Some sequences, like the first one go off to infinity, and others bounce around to multiple different targets, like the second one. But in some sequences, like the third, all the numbers eventually get very close together. We call those “Cauchy” sequences,8 and we want to have limits for all of them.
The definition of a Cauchy sequence may seem very similar to the definition of a limit, but it’s not quite the same. A sequence has a limit if the terms all get close to some fixed number; it’s Cauchy if the terms all get close to each other. In a Cauchy sequence, it seems like there should be some number the terms are getting close to, but in sets like the rational numbers, that may not be true. The rationals have “holes” that the terms of the sequence can gather around, but that don’t correspond to any rational number.
The most famous example is probably \(\sqrt{2}\). We saw last time that \(\sqrt{2}\) is irrational: there are no integers \(p\) and \(q\) such that \( \left( \frac{p}{q} \right)^2 = 2\). But we can find a rational number so that \(1.9 < (a_1)^2 < 2\), and then a second with \(1.99 < (a_2)^2 <2\), and a third with \(1.999 < (a_3)^2 <2\); and if we keep doing this, we get a sequence of numbers that clearly “wants to” converge to \(\sqrt{2}\).9 And that shouldn’t cause us too much distress. Even though \(\sqrt{2}\) is irrational, it’s an algebraic number, so we already created it; we don’t need to make up anything new.
But another hole in the rationals is \(\pi\). We built a Cauchy sequence of algebraic numbers that wants to converge to \(\pi\): \[ \left( 3, \quad 6 \sqrt{2-\sqrt{3}}, \quad 12 \sqrt{2-\sqrt{2+\sqrt{3}}}, \quad 24 \sqrt{2-\sqrt{2+\sqrt{2+\sqrt{3}}}}, \quad \dots \right) \]
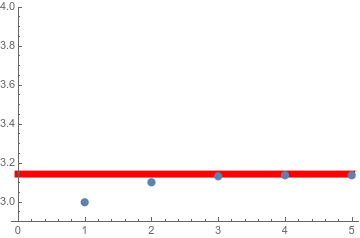
With a little more effort we could build a sequence of rational numbers that does the same thing. (For instance, as we’ll see later, \((3, 3.1, 3.14, 3.141, \dots )\) would work.) But \(\pi\) isn’t an algebraic number like \(\sqrt{2}\). From the algebraic perspective of part 1, it doesn’t exist.
But it should exist. So we’ll invent it.
You complete me
If we invent all the numbers like this that should be the limits of sequences, we get the real numbers, which we represent with the symbol \(\mathbb{R}\). And the real numbers are complete, which means that every Cauchy sequence—every sequence which ought to converge—does in fact converge.
From this perspective, we can say that a real number is just a Cauchy sequence. But that’s not a great way to talk about them, for two reasons. The first is just that it’s awkward. I don’t want to go around talking about the number \[ “\lim_{n \to \infty} \left( 3, \quad 6 \sqrt{2-\sqrt{3}}, \quad 12 \sqrt{2-\sqrt{2+\sqrt{3}}}, \quad 24 \sqrt{2-\sqrt{2+\sqrt{2+\sqrt{3}}}}, \quad \dots \right)”, \] and neither do you.
The second problem is that more than one sequence can converge to the same limit. \( (1, 1/2, 1/3, 1/4, \dots ) \) has the same limit as \((0,0,0,0, \dots ) \) or \( (1, 1/2, 1/4, 1/8, \dots )\); we really don’t want to treat them as different real numbers. We can fix this problem by defining real numbers to be “equivalence classes of Cauchy sequences of real numbers” but that gets extremely cumbersome.
The official method for constructing the reals is something called Dedekind cuts, where a real number is a way of cutting the rational numbers in half. So for example, we identify \(\sqrt[3]{2}\) with the set of all the rational numbers with \(x^3 < 2\). This has the advantage that it’s really easy to use in proofs; it has the disadvantage that it’s even more cumbersome to work with than the Cauchy sequences description.
But there’s a much easier approach. And it’s something we all learn in high school.
Decimalization
In high school algebra, I learned that a real number is an infinite decimal.10 Where does this idea come from?
We said that the real numbers are complete, which means every Cauchy sequence converges. But they’re also ordered: if we have two distinct real numbers, one will always be greater than the other. And that give us another way to characterize completeness:
Monotone Convergence Theorem: if a sequence of real numbers is increasing and bounded above, then it converges.
The idea here is that if a sequence is always increasing, it can’t really bounce around. So there are only two options: either it goes to infinity, or it converges to some real number. And this is basically how we actually got \(\pi\), right? Each polygon had a bigger perimeter than the last one, but the perimeter would never get bigger than, say, \(8\). We had an increasing sequence with an upper bound, so it had a limit.
Now a finite decimal is just a rational number. We can interpret a finite decimal \(3.14\) as something like \( \frac{314}{100},\) and similarly \(1.414 = \frac{1414}{1000}.\) But we can’t do the same thing with an infinite decimal; we’d have to have an infinitely large numerator and an infinitely large denominator.
Instead, we interpret an infinite decimal as a sequence. When we write that \(\pi = 3.14159 \dots,\) we mean that \(3\) is a rough approximation, and \(3.1\) is a better approximation, and \(3.14\) is even better; thus \(\pi\) is the limit of the sequence \((3,3.1, 3.14, 3.141, 3.1415, \dots). \)
Every infinite decimal is an increasing sequence, and every infinite decimal is bounded above: whatever we can say about a number like \(1.14142\dots\), we know it can’t be bigger than \(2\). So every infinite decimal corresponds to a real number.
And just as importantly, every real number corresponds to an infinite decimal! If we have a real number \(x\), we can find the biggest number with one decimal place that’s smaller than \(x\). Then we can find the biggest number with two decimal places, and the biggest with three, and the biggest with four… and this gives an infinite decimal that converges to \(x\).
Math’s greatest flame war
This construction generally does what we expect it to, but there’s one very special case where it doesn’t. We know \(1\) is a natural number, and thus a rational number, and thus a real number. So how do we write it as an infinite decimal?
The largest number with one decimal places that’s less than \(1\) is \(0.9\). With two decimal places, we get \(0.99\). With three we get \(0.999\). So by this construction, the infinite decimal representation of \(1\) is in fact \(0.999 \dots .\)
You may have run across this claim, that \(0.999 \dots~= 1\), before; and it almost always triggers a great deal of resistance. It must be smaller than one. The leading term is a zero!
You’ll sometimes see simple algebraic proofs like this:
\[
\begin{aligned}
10 \cdot 0.999 \dots & = 9.999 \dots \\\
9 \cdot 0.999 \dots & = (9.999 \dots) - (0.999 \dots) \\\
9 \cdot 0.999 \dots & = 9 \\\
0.999 \dots & = 9/9 = 1.
\end{aligned}
\]
But a lot of people find that unsatisfying and unconvincing.
In fact that argument is a little glib, and glosses over some fairly sophisticated ideas—which we just worked through.11 An infinite decimal is asking for a limit, which isn’t how people generally think of numbers. But it’s certainly true that \(1\) is approximated by \(0.9\), and approximated even better by \(0.99\), and even better by \(0.999\); and that we can make that approximation as good as we want by adding more \(9\)s to the decimal.
And that’s all the \(0.999\dots~ = 1\) actually means. The sentence seems weird, because real numbers are weird. They seem innocuous, but a single real number is secretly an infinite collection of infinite series. And if we look too closely, the weirdness starts leaking out.
Was this really necessary?
We started off with a fairly innocuous question: what is the area of a circle? And the answer turned out to be…quite a bit more complicated than we might have expected. And it gets worse! For instance, while there are infinitely many rational numbers, we can show that \(100\%\) of real numbers are irrational—and in fact \(100\%\) of them are, in a very precise sense, impossible to describe.
The real numbers are so weird and complicated that you might be wondering if we really need to do all of this. Sure, \(\pi\) is important, but can’t we just treat that as a one-off idiosyncrasy, and avoid all this nonsense about Cauchy sequences and Dedekind cuts? Unfortunately, we can’t. Sure, real numbers are extremely weird eldritch horrors horrors; but they’re also exactly the tool we need to do calculus.
There’s more to say about both of these ideas: why are the real numbers weird, and why are they so useful? So next time we’ll learn more about just how strange the real numbers are, and see why they are, nonetheless, perfectly suited to solve a whole host of very important problems.
Have questions? Can’t wait for part 3? Want to share your favorite weird numbers with me? Tweet me @ProfJayDaigle or leave a comment below.
-
No, not becuase everyone was exhausted by this point in the lesson. ↵Return to Post
-
A word I’m pretty sure I’d never heard before I just looked it up. ↵Return to Post
-
The paper How Archimedes showed that \(\pi\) is approximately equal to 22/7 by Damini D. B. and Abhishek Dhar was extremely helpful to me in putting this section together. ↵Return to Post
-
Just last week I told a student I had no memory of how to prove this. But the simple argument is precisely that we’re cutting an equilateral triangle in half—the half-triangle has an angle of thirty degrees and a side that has half the length of the hypotenuse. ↵Return to Post
-
Which I have to look up every time I want to use it. ↵Return to Post
-
Why 3.14 and not 6.28? The Greeks were more interested in the diameter of the circle than the radius, and so they thought the interesting formula was \(C = \pi d\), rather than \(C = 2 \pi r\).
Modern mathematicians generally see the radius as more fundamental, so we phrase all our formulas in terms of the radius; this means that a lot of our formulas contain the term \(2 \pi\). There’s a movement to stop using \(\pi\) and instead use the Greek letter \(\tau\) (tau) as the fundamental constant \(\tau = C/r = 2 \pi\). But it’s hard to change notation, so we slog on using \(\pi.\) ↵Return to Post
-
We can give a more precise definition using the Greek letter \(\varepsilon\), which is infamously confusing to calculus students. It’s really just a more precise way of saying the same thing.
We say that \(L\) is the limit of \( (a_n) \) if, for every \(\varepsilon >0\), there is a natural number \(N \) such that if \(n > N \) then \( \mid a_n -L \mid < \varepsilon\).
See if you can see why this means the same thing as the less formal version I wrote in the main text. ↵Return to Post
-
Pronounced “coh-shee”. They’re named after the 18th-century French mathematician Augustin-Louis Cauchy, who helped formalize this approach to limits and the real numbers. ↵Return to Post
-
But you can’t make the same argument for \(i\), the square root of \(-1\); this will be important next time. ↵Return to Post
-
Yes, even whole numbers are infinite decimals. We’ll get there. ↵Return to Post
-
A similar approach can also be used to “prove” that \(1+2+4+8+ \dots~ = -1\), which is obviously not what we mean. ↵Return to Post
Tags: math teaching calculus analysis philosophy of math